TIL 20231228
목록 전체 조회 하는 부분에 있어서 내림차순을 하는 거였는데, 처음에는 sortByDescending이라는 키워드를 이용해서 해보려고 했는데 잘 안되었다.. 어떤식으로 배치해야할지도 모르고 이게 맞나 싶어서 튜터님께 조언을 구했더니
jpa 의 ordey by 하는것을 찾아보면된다고 해주셨다.
아.. 아직 이런것도 검색하는 능력이 부족하니 문제다.. 그치만 이런 사소한 모르는 부분이더라도 알려고 튜터님께 달려가 질문을 한 건 내 자신에게 칭찬해줘야 된다고 생각한다.
그래서 어찌됐든 검색해봤더니! findAll은 기본적으로 Sort를 지원하고 있어서 findAll 내부에 정렬하는 코드를 입력해주면 된다고 한다. 참고로 Sort.Direction.DESC는 내림차순 정렬이고 Sort.Direction.ASC는 오름차순 정렬이다. 정렬 기준이 될 컬럼명을 입력해주면 된다. 과제 내용에서는 작성일 기준이라고 하였으므로 나는 day라고 작성 해주었다!!
todoRepository.findAll(Sort.by(Sort.Direction.DESC,"day")).map { it.toResponse() }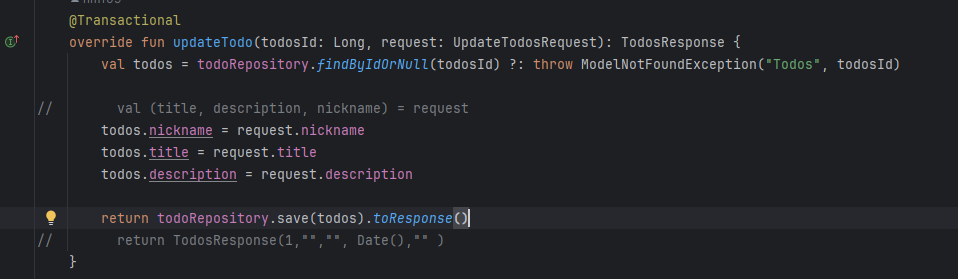
튜터님께 숙제를 받았다. 이 업데이트 부분에서 return 부분에 save가 있어서 저장하는 걸로 되어있는데,
save를 지워도? 저장이 되냐고 여쭤보셨다.
실제로 위의 return 부분을 주석처리 하고 아래 글을 리턴 하니 실제로 저장되는 것이 아니겠는가!
정말 신기했다... 이래도 저장이 되는구나 싶어가지고,, 이 이유를 찾아오라는 것이 숙제였다.
JPA 특징 중 영속성 컨텍스트라는 것과 더티체킹이라는 것이 있다.
영속석 컨텐스트는 일종의 논리적인 임시 저장소 공간을 통해 관계형 데이터를 객체 (Object) 로 맵핑해 관리하는 것이며
더티체킹은 상태변경검사로, 영속성 컨테이너가 관리하는 엔티티의 상태를 감지해서, 변경된 부분이 있다면 자동으로 트랜잭션이 끝나는 시점에 데이터베이스에 반영하는 기능이다..
이어서 말하자면,
JPA 의 Persistence Context
정의한 Entity는 어떻게 관리가 될까?
이때 등장하는 개념이 영속성 컨텍스트(Persistence Context)라는 개념이다.
애플리케이션 내에 변수로 데이터를 저장하고 관리하면 어떻게 될까? 이 데이터는 메모리에서 관리되기 때문에 애플리케이션이 종료되면, 해당 데이터는 모두 사라지지 않겠는가? 이때 ‘영속성’이 없다고 말한다. 반대로 해당 데이터를 데이터베이스에 저장함으로써 ‘영속성’을 부여할 수 있다.
JPA는 Entity가 이 영속성 컨텍스트에 포함되어 있는지, 아닌지에 따라 데이터베이스에 변경사항을 저장하여 영속성을 부여할지, 말지를 결정한다. 예를들어, 한 트랜잭션안에서 데이터를 데이터베이스로부터 가져올 때 이 데이터는 영속성 컨텍스트에 포함된 상태고, 최종적으로 값을 변경하고 트랜잭션이 끝날 때 데이터베이스에 변경사항이 반영된다.
JPA는 이 영속성 컨텍스트라는 개념을 활용해 아래의 역할들을 수행한다.
Entity의 상태 추적
영속성 컨텍스트는 Entity가 Transient(New), Managed, Detached, Removed 등의 상태에 있는지 추적한다.
Transient: 아직 영속성 컨텍스트에 포함되지 않은 새로운 Entity 상태입니다.
Managed: 영속성 컨텍스트에 저장된 상태입니다.
Detached: 영속성 컨텍스트에 저장되었다가 분리된 상태입니다.
Removed: 삭제된 상태입니다.
JPA는 이런 Entity의 상태를 통해 트랜잭션 종료시 DB에 최종적으로 어떤 쿼리를 날릴지를 결정한다.
최종적으로, 트랜잭션이 끝나는 시점에 Managed, Removed 상태의 Entity들의 변경사항이 데이터베이스에 반영된다.
캐싱(Caching)
영속성 컨텍스트 내에 Entity를 Map 형태로 임시 저장하여 동일한 Entity를 조회할 시, 데이터베이스를 직접 조회하지 않고 해당 Entity를 사용할 수 있게한다.
지연 로딩(Lazy Loading) 및 즉시 로딩(Eager Loading)
연관관계에 있는 Entity 를 지연로딩하거나 즉시 로딩할 수 있는 기능을 제공한다. 지연 로딩은, 연관된 Entity가 실제로 필요한 시점에 데이터베이스에서 로드를 할 수 있도록한다.
예제로, 아래의 코드를 보면,
첫번째 라인은 post를 조회하는 역할을 하는데.... 이 때, 실제로 SELECT * FROM POST WHRE id = :postId 와 같은 쿼리가 실행된다....!
.
두번째 라인은 post와 연관된 author를 조회합니다. 이때, 지연로딩을 설정했을시에 쿼리는 실행되지 않는다. JPA는 프록시 객체 라는 개념을 활용하여 가상의 객체를 대신에 로딩해둔다.
세번째 라인에서 실제로 author의 필드에 접근한다. 이때가 바로 실제 객체가 필요한 시점인데, 이때 author를 조회하는 쿼리가 수행된다!
// 1.
val post = em.find(Post::class.java, postId)
// 2.
val author = post.author
// 3.
val authorName = author.name
즉시, 로딩은 지연 로딩과 반대로 연관 Entity에 접근하는 순간에 쿼리가 수행된다!
트랜잭션(Transaction)을 통한 쓰기 지연
전에 이미 @Transactional 어노테이션을 배웠는데,,, 지연로딩과 유사하게 코드 상에서 Entity를 수정하거나 변경한다고 바로 반영하지 않고, Entity의 상태 변경을 통해 SQL 저장소에 쿼리를 저장해둔다.
최종적으로 트랜잭션이 종료되는 시점, 즉 트랜잭션을 최종 commit() 하기 이전에 데이터베이스에 모아둔 쿼리를 보내 데이터베이스와 영속성 컨텍스트를 동기화 한다. 최종적으로 commit() 이 종료되면, 데이터베이스에 변경이 반영된다. 이렇게 commit() 종료 이전에 쿼리를 보내 동기화를 하는것을 flush() 라고 표현한다. flush() 로 전송된 쿼리는 Rollback이 가능하지만, commit() 이 완료되면 트랜잭션이 끝나므로 Rollback 을 할 수 없다.
Dirty Checking
flush() 는 어떻게 어떤 쿼리를 보내야하는지를 판단할 수 있을까? Entity의 변경 사항을 추적해서 판단한다. 이 과정을 Dirty Checking이라 한다.
예를들어, 아래처럼 post의 title을 변경했을시에, Dirty Checking을 통해 아, post의 title이 변경되었느니 update 쿼리를 실행해야겠구나! 를 판단하는 것이다....
val post = em.find(Post::class.java, postId)
println(post.title) // "Title1"
post.title = "New Title2"
주의 할 점으로 알아야 하는 것은, Dirty Checking은 Entity가 영속성 컨텍스트에 저장된 상태, 즉 Managed 상태에 대해서만 수행된다고 한다.
영속성 컨텍스트(Persistence Context)를 두어 Entity를 관리하는 주체가 바로 Entity Manager인데,
@PersistenceContext 어노테이션을 통해 주입할 수도 있고, 생성자 주입을 했을시에도 자동적으로 주입이 된다.
import org.springframework.stereotype.Service
import jakarta.persistence.EntityManager
import jakarta.persistence.PersistenceContext
@Service
class MyService {
@PersistenceContext
private lateinit var entityManager: EntityManager
}

- persist() : Entity를 영속성 컨텍스트에 추가힌다.
- merge() : Detached 상태의 Entity를 다시 영속성 컨텍스트에 추가하여, 변경이 감지되도록 한다.
- remove() : Entity를 삭제한다.
- detach() : 영속성 컨텍스트에서 Entity를 분리하여 Detached 상태로 만든다.
- clear() : 영속성 컨텍스트를 초기화하여 모든 Entity를 Detached 상태로 만든다.
- close() : EntityManger를 종료한다.
- flush() : 영속성 컨텍스트 내에서 변경된 Entity를 감지하여 데이터베이스와 동기화한다.
- find() : 주어진 Entity의 PK를 이용하여 Entity를 데이터베이스에서 조회하여 영속성 컨텍스트에 추가한다.
참고-- flush는 쓰기 지연된 쿼리 저장소에 쿼리를 쌓지 않고 데이터베이스에 바로 실행한다.. 하지만 영속성 컨텍스트는 트랜잭션 범위 안에서만 동작하기 때문에 쿼리가 실행된다고 하더라도 실제 영속화는 일어나지 않은 상태이다.
엔티티를 신규로 생성 했다면 해당 엔티티는 아직 관리 대상이 아니기 때문에 repository 를 통해 영속화를 시키겠다고 명시를 해줘야 한다.